Handling Redis messages in parallel
In the last post it looked like the rate of submission and completion of tasks was constant in time, but that the rate of completion of workflows was not.
There are two end member scenarios: if tasks were completed in strict workflow order then there’d be a steady progression of workflows completing, giving a constant rate; alternatively, if the first 8 tasks in every workflow were completed first, and the last task only started when every other workflow had been touched, then all workflows would complete almost instantaneously right at the end of the run. What I saw in the last results might represent a balance between the two.
The workflow completion behaviour might also be controlled or modified by the messages in flight from Redis, and by the way these are both published and picked up by the client StackExchange.Redis. I’m assuming that Redis will not stall while it passes a given message to every consumer subscribed, and I’m assuming that StackExchange.Redis will make a separately-threaded callback into my code whenever a message is received, probably subject to some throttling.
There are a couple of things there that I can check. One is the number of running tasks at each moment; if we’re handling these in a multithreaded way (via StackExchange.Redis – there’s no such behaviour in the benchmark app yet) then it should be observable. The other thing to check is the size of the submitted queue.
I added some instrumentation to my benchmark app to output these and, voila:
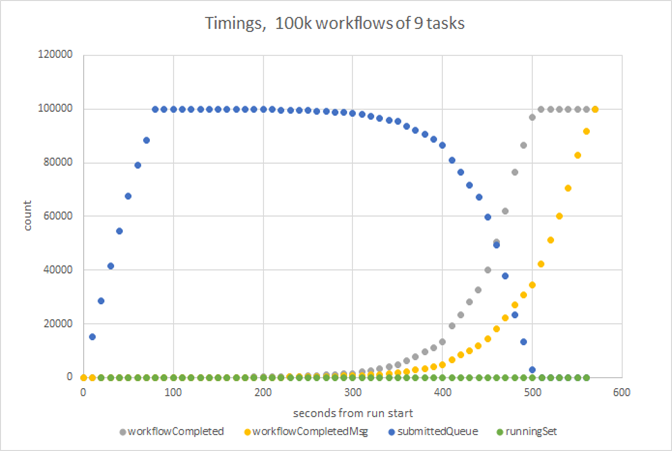
The submitted queue size reaches a plateau then hovers there, which intuitively means that across all workflows we’re finishing one task and replacing it with another in the submitted queue. It tails off roughly in line with the workflow completion curve.
One very interesting point to take away there is that the number of running tasks at any time is 1.
That indicates that somewhere the processing of tasks is either bottlenecked or significantly throttled. I’m not doing anything in my app. Is StackExchange.Redis serializing the handling of the returned messages?
It turns out that it is. By default, StackExchange.Redis forces subscribed message handling to be sequential, principally because it’s safer: it stops clients having to worry about thread conflicts when processing the messages.
However, when you want to scale out it makes sense to let go and account for possible threading issues by design. In this case, each workflow task is intended to be a unit independent of any other, and so they’re embarrassingly parallelisable. In fact, currently the creation of the multiplexer is in the hand of the client, so they can make the choice themselves.
If I set ConnectionMultiplexer.PreserveAsyncOrder = false in the benchmark app, things improve considerably. Task churn leaps to 4k per second; the whole run completes sooner (210 seconds) with the push only finishing at 168 seconds.
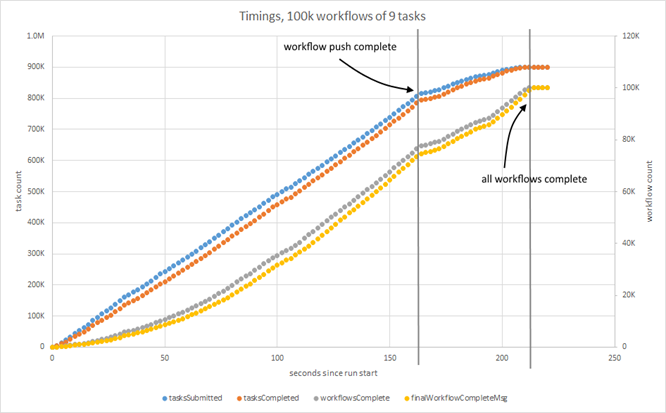
There’s a lot less dispersion in the message handling – the workflow complete queues are much tighter, and the count of tasks completing follows the submitted count much more closely. After a suppressed start the system completes workflows at a steady rate.
For the bulk of the run task submission and completion, and workflow completion, proceed at a constant rate. That indicates that this solution might scale out with an increasing number of tasks or workflows.
It’s not all sunshine and rainbows. When repeated I’ve seen occasional timeouts which currently bring the workflows down. Superficially they seem to be correlated with the points at which Redis forks and saves out its logs – typically I see error messages like
Timeout performing EVAL, inst: 1, mgr: ExecuteSelect, err: never,
queue: 22, qu: 0, qs: 22, qc: 0, wr: 0, wq: 0, in: 0, ar: 0,
IOCP: (Busy=0,Free=1000,Min=4,Max=1000),
WORKER: (Busy=20,Free=2027,Min=4,Max=2047), clientName: TIM-LAPTOP
This seems to indicate that 22 commands have been sent to the server (qs), but no response has been received (in); consequently it might worth increasing the timeout. If it is related to the Redis background fork-and-save, perhaps there’s something I can do there too.