Pausing for thought
This post relates to code changes in this commit to my redis workflow project on GitHub, under this issue .
In my workflow project it’s time to consider how to pause a given workflow, and the first thing is to decide on what pause actually means.
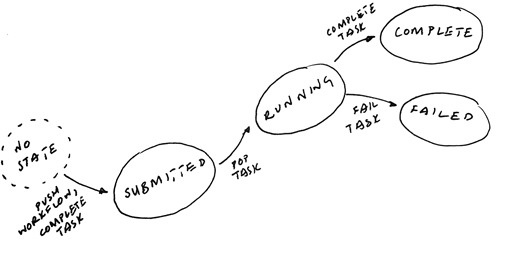
At first sight it means “hold everything that’s running” and “stop anything new from starting”, but that turns out to be difficult to implement effectively generally, and has some particular wrinkles when using Redis.
It looks easy to stop anything new from starting: I can move all tasks for a given workflow to a state that means they won’t get picked up; let’s say that state is labelled paused, because frankly, this gets complicated enough. To release the tasks all I’ll need to do is move all the paused tasks for this workflow back to the submitted state.
Except: the fact I’m asking for all the submitted (or paused) tasks for a specific workflow means we have a decision to make. At the point of time this functionality was added all these tasks were together in a global submitted state. I could loop through every id in the submitted set, use those ids to lookup tasks and fetch their workflow ids, then decide whether each one needs to be acted on.
Alternatively I could populate an additional set when tasks transition to each new state, keyed by workflow id. When tasks in workflow 1 move to the submitted state, for example, we could add them to a distinct set with key submitted:1. That makes finding tasks in a specific state for a specific workflow much easier, and is the approach I’m taking. It means S x W new sets at worst, where S is the number of states and W the number of workflows. At the scale I’m aiming for that means ~600,000 sets, assuming no clean-up after workflows.
So, when someone asks to pause a workflow we’ll just shift all tasks from submitted state to paused, yes? And on release, we should just move everything from paused to submitted? Not quite.
I’m deciding to let running tasks run to completion. As currently running tasks complete (or fail) they might cause further tasks to be submitted, which isn’t the behaviour we want. It makes sense then to have the completion logic know that if the completed task has moved to the paused state then it shouldn’t cause its dependencies to be submitted, although it can be transitioned to is final desired end state (complete, or failed).
However, when it comes to releasing the workflow again, what should happen to the children of those completed tasks, if all their parents have completed? If I don’t do something then they won’t get picked up when someone asks to release the workflow – there’s nothing left to complete and trigger their submission.
Instead, if a paused task completes and its children become eligible for submission they should be placed in the paused state themselves. Then, when someone requests that the workflow be released, they’ll shift back to the submitted state.
On release, then, that takes care of ensuring I don’t lose track of any tasks, assuming that the release command comes after all outstanding running tasks have completed.
If the release request comes while tasks are still running down, however, releasing the workflow will be difficult. We won’t know whether to move the tasks to the submitted or running state, because there’s no differentiation in source state for tasks in the paused set. We’ve lost that information. If we shift a task that’s being executed somewhere to the submitted state on release then it might get run twice in parallel, or get confused when it comes to submit and finds it’s not in an expected state.
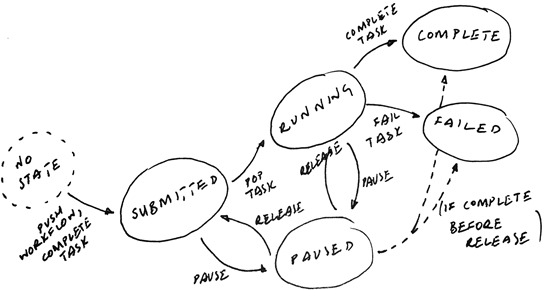
The (hopefully) final puzzle piece is then to record the last state of each task, so when a release request is issued we can move it back to the appropriate state. Running tasks should get moved back to running, submitted tasks to submitted. Tasks that have completed already won’t be in the paused state, so won’t get considered for release, and we’ll need to tag newly runnable tasks with a fake last state of submitted.
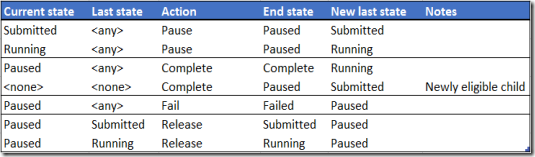
That should means we don’t lose any information about the state of the workflow during pause and release operations. For such a simple thing it’s still quite possible to get wrong; making a few assumptions and decisions explicitly helps a great deal. I decided to:
- Stop anything new from starting.
- Let executing tasks run to completion.
- Create lookups to answer specific questions.
- Avoid duplicate task execution. </ul> all of which seem reasonable currently; let’s see how the next chunk of functionality changes that.