Deadlocks, rowlocks and indexes, and keys
Away from workflows for a moment, and another chance to see how a little bit of knowledge is sometimes a dangerous thing. Maybe that’s a bit harsh; maybe just a chance to remember that pausing to think “is that definitely the underlying problem?” and taking your hands off the keyboard is generally a good idea.
Recently I added a couple of results tables to a database; one field was shared between the two and could be normalized out with an independent identity-driven table rather than repeating the source data string row by row. All fine and good; I structured the stored procedures used to enter data into the table such that they insert new field values into the normalized table first if needs be, and then the actual data is entered using a join on that table. For sake of an example, let’s call this field NettingSetID, and have two results tables that use it, as well as referencing a normalized NettingSet table. Broadly like:
with SQL to insert something like
Sadly, I saw it generate deadlocks on data insert. Not every time, but frequently enough. Inserts were coming in in parallel, but each parallel insert was independent in terms of NettingSet. I couldn’t guess off-hand what was happening. You don’t get a whole lot of information back from a bland deadlock victim message from SQL Server.
What was happening?
I started SQL Profiler, excluded all metrics then added Locks/Deadlock Graph, and set it running …
For reference – if you want to cause a deadlock just to see what can be done to fix it, there’s a great example of causing a deadlock on StackOverflow asked as How to deliberately cause a deadlock?. Backing up significantly, if you don’t know what a deadlock is then try asking after the Dining Philosophers, maybe in the Little Book of Semaphores. Finally, Jeff Atwood and Brad McGehee have a couple of great articles on the problem, one at Coding Horror and one in much more detail, here.
.. and soon started seeing deadlocks appearing.
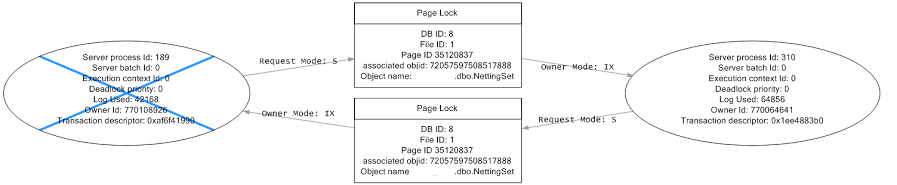
The first interesting (perhaps not surprising) piece of information that the resource under contention was the NettingSet table. The second interesting piece of information was that both are trying to take a Shared lock on the same page that the other had eXclusively locked with Intent to write.
At that point, I should have realised that I didn’t understand locking in SQL Server.
The deadlock graph is showing that two intent locks have been taken on the same page. SQL Server automatically places intent locks at page level to cover operations on rows or indexes in that page, so seeing two processes with an intent lock on the same page is not unusual.
The problem is that the shared read lock is also being taken out at page level. Why? I still have no idea. It’s not trivially repeatable – that is, I haven’t been able to set up a simple model system in which it happens every time. With hindsight I can only guess that it’s something to do with the primary key placed on the NettingSet table. More on that later.
At the time though, with relatively limited information to go on, I thought page locks – shouldn’t they be row locks?
Should be rowlocks?
After a little thought I figured that it should only be taking row locks, and so I added a with (rowlock) hint. Quick rerun and – success! No more deadlocks.
Except of course for the fact that to do a proper test I needed to remove the data that had been placed in the NettingSet table. After clearing that out, the deadlocks were back, and still at page lock level. Guessing (there’s no other word for it) that we were getting lock escalation because of the select I added hints there too – with (updlock, readpast).
Success, with a side of fail
It worked. It worked after clearing down the NettingSet table. It worked right up to the point where I realised there were duplicate entries going into the NettingSet table.
This was also the point I realised I didn’t understand locking in SQL Server.
Then a penny dropped, and I looked at the primary key for NettingSet. Identity and Name. All I want are unique names; as long as they’re unique, then the identity created should be unique too. I assumed the hints I added to the select allowed it to merrily skip past the pages that were locked – containing the data that had already been inserted – and, finding nothing, happily give the all clear to insert again.
I dropped the primary key and recreated it without the ID column. I removed all the with (rowlock) and with (updlock, readpast). And it worked fine. No more deadlocks.
This still isn’t quite right, however.
Almost There
The ID identity field should be unique, as that’s what the Result table should be keying against. The Name field needs to be unique because there’s simply no need for duplicate Name entries, and indexed because it’s searched against. I decided to make Name the primary key because it seems like the natural key for the table – but there’s an awful lot of discussion out there about whether natural or artificial keys are most appropriate as primary keys.
With this in place I still don’t see deadlocks, and the data’s structured more sensibly.
What did I learn?
Not thinking about data structures carefully when you create them might lead you to create something that fulfills the requirements of a test, but also something that represents a great way of wasting a couple of hours if you don’t get the basics right.
Even at the point of creating duplicate rows everything was technically working – a query against the data would return a full data set, with appropriate NettingSet Name. It’s only because I knew a priori that there shouldn’t be duplicate rows that I kept going with it. The tests I had wouldn’t show it up. From a business point of view the right data would be coming back, but to me everything would be wrong about the implementation. That said: what is the wrong implementation? That kind of question is at the core of what we do as developers currently.
It was only while writing this blog post that I began to realise that I had no idea why SQL Server was taking the locks it did. It’s possible that I’d have got to the answer sooner if I’d been able to figure it out. If nothing else – I’m even more certain I’m not a SQL Server expert now – I’ve learnt a useful rule of thumb: that when I see deadlocks I shouldn’t by default try and work around SQL Server’s locking mechanism. Instead, I should check to make sure the data structures I’m using are well constructed.
Sadly, I’m still none the wiser about exactly why SQL Server wanted to take out shared locks at page level. I’ll have to get some reading done, starting with “Inside SQL Server 2005: The Storage Engine”.