Getting your priorities right
I want to take a look at implementing some means of handling prioritisation in my workflow project redis.workflow.
Currently redis.workflow is all about throughput; all workflows and all tasks have the same priority. In some cases this is fine. If you have a known whole workload at time T that should deliver results by time T+1 then it doesn’t really matter which order you complete them in. The goal in such a context between maintaining a high utilisation of resources and horizontal scaleout to manage load.
It’s not always just about throughput
However, there contexts in which pure throughput isn’t enough. Sometimes its social: someone arbitrarily wants to see a graph showing a steady completion of recognizable sets of workflows. Sometimes it’s based on an understanding of the workload: not all workloads are heterogeneous, and might have long-tail task duration distributions; and those long runners will breach your delivery SLA if you start them too late. Sometimes you have combined workloads: the system might be responsible for both batch throughput calculations and ad-hoc calculations issued directly by someone who’s waiting for an answer, and wants some guarantee that they’re not wedged behind a freight train of batch work. Sometimes it’s simply SLA based: you have 24 hours worth of work, but some of it needs to be delivered by 8am, and some of it by 5pm.
In many ways then a pure throughput system might not meet all requirements, and in each of the scenarios above a decision needs to be made about each item of work: do I need to get this work done first, or that? The system needs to understand work priority.
What has priority?
It’s worth considering where the priority lies. As work is being submited to redis.workflow at workflow level, then it might seem natural to prioritise at workflow level. It is, however, as easy to implement task-level prioritisation as it it to implement workflow-level prioritisation from a development perspective; from a load perspective there’s more to do though as the number of tasks is generally greater than the number of workflows.
In the end, prioritising at task level gives me more flexibility. It also supports use cases I’ve seen in the field; one client needed to have all tasks of a certain type complete before other tasks were considered, for example. I (or any client) could replicate workflow-level prioritisation by giving every task in a workflow the same priority.
Prioritisation itself can be simple or sophisticated, partly depending on the granularity required. That requirement can significantly alter how we structure the relevant data in Redis.
Fine- or coarse-grained priorities
Currently redis.workflow uses a queue of submitted tasks, which is fine for a simple throughput scenario. I could extend it to make practical binary priority decisions by enqueuing high priority tasks at the front of the queue, and low priority tasks at the back, without the need for a new structure.
If finer-grained priorities are required then things get a little harder. If the number of levels of priority is small then having a queue per priority might be feasible; in fact, combined with the enqueue-to-front-or-back trick you only need half the number of queues as you have priority levels.
If very fine-grained or arbitrary priorities are needed, then I’d need to start thinking about maintaining relative order in the queue or list. Insertion at a given priority could happen between work of higher and lower priority, which would require iterating through the list to work out where to put it, or just enqueuing, then sorting the list. That’s likely to perform underwhelmingly; a more sophisticated solution would be to add a lookup that identifies priority boundaries by queue position.
Each of these is a reasonable way of managing prioritised work. Clearly enabling the use of arbitrary priorities would allow clients to choose, and even use simpler (say binary or even fall back to unary) prioritisation, but come at a cost in terms of complexity.
The binary high/low priority solution – enqueuing to front or back – is relatively easy to imagine in my existing code, as it’s already placing work at the back. Jumping to arbitrary priorities is harder, but it’s worth considering what would need to be done.
To manage arbitrarily prioritised work, I’d need to sort the work submitted in some way. Redis does have a sorted set, which offers O(log N) lookup and insertion by score. I’d need to be able to remove the highest-scoring task, which I would be able to do with
except that there’s no limit out-of-the-box for zremrangebyscore. Instead, I’d have to use zrange to return a sorted list of items (although this sorts from lowest to highest score, meaning I need to decide whether 0 is low or high priority) then use zrem to remove the task.
Starvation
If you’ve done this before you might have noticed that there’s no handling of low-priority starvation here. I’m explicitly not handling it, and assuming that either the workload is known in advance and just needs ordering, or that ad-hoc high priority work is scarce compared to the bulk. If it turned out that in reality a given system were being starved of resources for low priority work then I’d look at some way of dedicating/preferring resources for lower priority work, up to and including having separate instances for throughput and ad-hoc workloads.
Ultimately starvation symptoms would imply that there weren’t enough resources available to do the whole workload, so we’d need to carefully evaluate the efficiency of existing resource use, then potentially consider finding additional capacity.
Effect of implementing arbitrary prioritisation with a SortedSet
I implemented this sorted-set-based prioritisation and ran it thorugh the benchmark app, giving each task the same priority. It was noticeably slower, taking about 485 seconds to run through the benchmark (a churn of about 1.8k tasks per second). Task and actual workflow completion seemed to keep pace with submission, but handling of the messages announcing workflow completion seems to fall behind, suggesting that it’s not scaling well in this example.
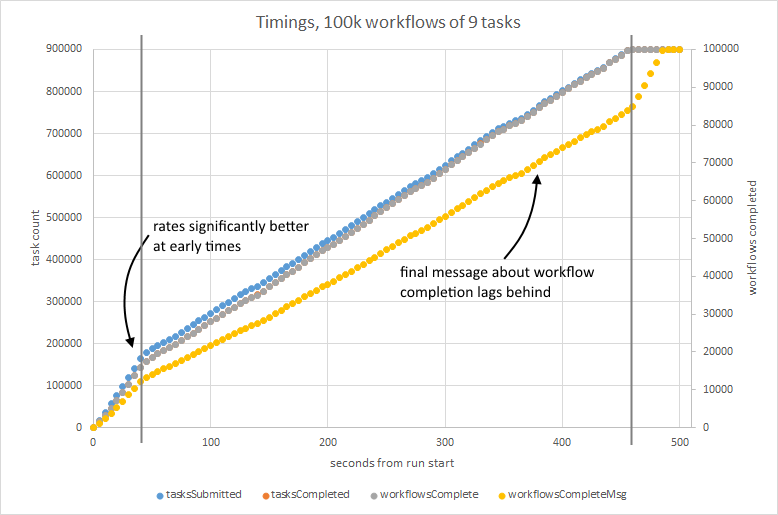
The benchmark needs to be extended to test workflows with varying numbers of tasks, and tasks with varying priorities.
Prioritisation, but at a price
For this moment I think that’s enough; there’s a wide range of ways of tackling the prioritisation problem, but the implementation of each is fairly straightforward in Redis. The way I’ve implemented it gives it a certain amount of flexibility – a client can configure priority at task or workflow level, but does slow things down. It’s possible the other, simpler methods have a less detrimental effect on performance; as the difference in performance is so significant it might make sense to consider making use of prioritisation configurable, although that’ll be difficult as it has fundamental consequences for the structure of the data in Redis.